
Apache Iceberg in Modern Data Architectures: A Comprehensive Report


Apache Iceberg has rapidly become one of the most talked-about technologies in data architecture over the past few years. As organizations shift towards data lakehouse designs that combine the scalability of data lakes with the reliability of data warehouses, open table formats like Iceberg play a pivotal role. Apache Iceberg is an open-source table format that brings SQL table-like functionality (transactions, schema management, etc.) to large analytic datasets on inexpensive storage (e.g. cloud object stores). Its rise in popularity is driven by the promise of high-performance analytics without vendor lock-in, allowing multiple processing engines to work reliably on the same data. This report delves into what Iceberg is and why it’s in high demand, examines the latest integration with DuckDB (as of April 2025), explores ideal technology combinations for lakehouse, streaming, and analytics use cases (in cloud and hybrid environments), and surveys other key technologies in the Iceberg ecosystem (Spark, Trino, Flink, Snowflake, BigQuery, etc.). We also highlight tooling and adoption by major organizations (especially for AI/ML workflows), and provide summary-level insights into Iceberg’s architecture and performance that explain how it all works together.
What is Apache Iceberg and Why Is It in High Demand?
Apache Iceberg is a high-performance open table format for huge analytic tables, originally developed at Netflix and now an Apache Software Foundation project. In essence, Iceberg is a “smart” layer between raw storage (files in formats like Parquet or ORC) and compute engines. It tracks table data and metadata to ensure that multiple analytics applications can all see a consistent view of data and perform ACID transactions on a data lake. This effectively brings the reliability and simplicity of traditional SQL tables to big data stored in distributed files.
Core Features of Apache Iceberg:
ACID Transactions & Snapshot Isolation: Iceberg allows atomic adds, deletes, and updates to table data, even with concurrent writers, ensuring readers never see partial updates. Each commit creates a new snapshot of the table, and readers can isolate to a specific snapshot, so queries are always consistent and never see “in-progress” data. This means multiple engines or jobs can write to the same table safely, and readers won’t get corrupted or “zombie” data.
Schema Evolution: Iceberg natively supports evolving the table schema over time (adding, dropping, or renaming columns) without cumbersome rebuilds. It tracks schema changes as part of the metadata. This reliable schema evolution avoids the headaches of older Hive-style tables where schema changes could be error-prone.
Time Travel & Rollbacks: Every snapshot of the table is retained, enabling time travel queries – you can query data as of a particular snapshot or time in the past. This is invaluable for auditing and reproducing experiments. It’s also possible to rollback a table to a previous state instantly if a bad data load occurs.
Hidden Partitioning & Evolution: Iceberg manages partition information internally rather than relying on physical folder structures. This means users get automatic partition pruning for queries, and partition schemes can be changed as data and query patterns evolve. There’s no need for manual “repair” or handling of Hive partitions – no more expensive directory listings or strict naming conventions. This dramatically reduces the load on metastores and speeds up query planning for large tables.
Metadata for Performance: Iceberg maintains detailed metadata (in manifest files and manifest lists) about the locations and statistics of data files. Query engines leverage this for advanced planning and filtering, skipping over unrelated files and only reading the necessary subsets of data. For example, Iceberg can avoid scanning thousands of file paths on cloud storage and instead quickly identify which files contain relevant data, eliminating the costly “full directory scan” that plagued older data lakes.
Scalability to Petabytes: Iceberg is designed for petabyte-scale datasets that are “slow-moving” (very large but append/modify occasionally). By tracking individual data files and optimizing how new data is added, Iceberg can handle tables with millions of files and enormous throughput. It also supports features like compaction (merging small files) and split planning to maintain performance at scale.
These features make Iceberg extremely attractive to data engineering teams. It directly addresses the limitations of earlier “open table” approaches (e.g. Hive tables or home-grown metadata), delivering database-like reliability on a data lake. As a result, demand for Iceberg has surged. Organizations want the flexibility of keeping data in open file formats on cheap storage, but with the manageability and trust of a warehouse. Iceberg provides this balance in a fully open standard, avoiding lock-in to any single vendor or engine.
Why the High Demand? A few key reasons stand out:
Multi-Engine Interoperability: Iceberg was built to be engine-agnostic – many different processing engines can read and write Iceberg tables and all see the same consistent data. This “define once, use anywhere” approach means companies can adopt best-of-breed tools for each job (Spark for ETL, Trino for SQL, etc.) without duplicating data. It unlocks the elusive goal of a true open lakehouse. The excitement around Iceberg has grown as major engines and platforms announced support, confirming it’s not a niche technology. By 2025, virtually every big data platform either supports Iceberg or has plans to: Databricks, Snowflake, Google BigQuery, Amazon Athena/Glue, Apache Spark, Flink, Trino, Presto, and more have all added Iceberg compatibility. This broad adoption across the industry has accelerated interest in Iceberg as a new standard.
Reliability and Performance Improvements: Early adopters like Netflix, Airbnb, and LinkedIn report significant improvements in data reliability and query performance after migrating to Iceberg. For example, Airbnb eliminated heavy Hive Metastore load and latency by replacing Hive tables with Iceberg (no more listing thousands of S3 partitions). Netflix was able to build a streamlined incremental ETL pipeline with Iceberg that improved data freshness and accuracy for its analysts and data scientists. These success stories have made Iceberg a go-to solution for organizations struggling with “data swamp” issues in their data lakes.
Scale for Modern Analytics and AI: Iceberg’s ability to efficiently manage petabyte-scale datasets and keep query speeds high is crucial for modern analytics, including AI/ML workloads. Machine learning models often need access to large historical datasets for training; Iceberg’s time travel and optimized storage layout make those accesses both faster and cheaper. The format ensures data consistency and quality (no partial updates, no corruption), which is critical for reproducible ML experiments. As one analysis notes, Iceberg’s robust framework for managing large datasets leads to faster and more accurate model training and inference, and this is a big reason it’s becoming a preferred choice for data lakes aimed at AI. Companies like Apple, Stripe, Expedia, Adobe, and LinkedIn have all embraced Iceberg in parts of their data platforms, underlining its effectiveness and versatility.
In short, Apache Iceberg brings order to the chaos of big data file lakes. It provides warehouse-grade features in an open format, enabling a new generation of data architecture where various tools can share a single source of truth. This unique value proposition explains the intense demand and rapid growth in adoption we’re witnessing.
DuckDB Meets Iceberg: New Integration in April 2025
One of the most exciting recent developments is the integration of DuckDB with Apache Iceberg. DuckDB is an in-process analytical SQL database (often called “SQLite for analytics”) known for its speed and ease of use, especially in data science workflows. As of early 2025, DuckDB gained the ability to read Iceberg tables directly, including those stored remotely on cloud object storage. This new feature, introduced as a preview in DuckDB version 1.2.x, allows users to attach Iceberg catalogs and query them with DuckDB’s SQL engine.
Technical Capabilities: DuckDB’s Iceberg integration is provided via an iceberg extension. Initially, DuckDB could read Iceberg tables (since late 2023) if pointed to local metadata. The April 2025 update adds support for Iceberg REST Catalogs, which is a big leap forward. An Iceberg REST catalog is a service (defined by the Iceberg community) that exposes table metadata through a REST API. DuckDB can now ATTACH to such a catalog with a single command, even if the data and metadata reside in cloud storage. In practical terms, this means DuckDB can connect to Amazon S3-hosted Iceberg tables or those managed via AWS Glue Catalog (which is used by AWS’s “S3 Tables” and SageMaker Lakehouse) as if they were local databases. For example, a user can run:
ATTACH 'arn:aws:s3tables:us-east-1:123456789012:bucket/my-iceberg-bucket' AS mydb
(TYPE iceberg, ENDPOINT_TYPE s3_tables);and immediately query mydb.my_table in DuckDB, pulling data from S3. DuckDB handles the Iceberg metadata and reads the Parquet files over HTTP/S3. It even supports Iceberg’s schema evolution – if the table’s schema is altered by another engine, DuckDB will pick up the change on next query, as demonstrated in tests with adding new columns.
This integration was developed in collaboration with AWS and coincided with AWS’s own announcements of Iceberg support. In March 2025, AWS introduced Amazon S3 Tables (an Iceberg-backed table service on S3) and its integration with SageMaker Lakehouse (AWS Glue as the metadata catalog). DuckDB’s team worked with AWS to ensure DuckDB could serve as an “end-to-end solution” for reading those Iceberg tables. The result is that DuckDB can query Iceberg data natively, without any Spark or Hive in the middle, bringing truly democratized access to lakehouse data.
Practical Implications: This development has several important implications:
Lightweight Analytics on Data Lakes: Now a data analyst with a Jupyter notebook can connect to a massive Iceberg table on S3 using DuckDB on their laptop. There’s no need to spin up a heavy Spark cluster or Trino service for interactive analysis. This lowers the barrier to entry for ad-hoc analytics on the data lake. DuckDB’s efficient vectorized engine can handle surprisingly large queries, especially with its ability to push down filters to the Iceberg metadata (e.g. it will only fetch relevant Parquet files). In short, cheap, user-friendly SQL analytics directly on the data lake becomes possible.
Integration with Python/AI Workflows: DuckDB is often embedded in Python environments. With Iceberg support, Python data science workflows (Pandas, Polars, etc.) can pull in fresh data from the lakehouse on demand via DuckDB, all while respecting snapshot consistency. For AI/ML experiments, this means you can directly query feature data or training data that’s stored in Iceberg format, using simple SQL, and get the benefit of Iceberg’s versioning (e.g. load the exact snapshot of data that a model was trained on).
Cloud/On-Prem Hybrid Access: Because DuckDB is just a library, you could run it anywhere – on your local machine, on an edge server, or within a cloud function – and attach to the same Iceberg table in the cloud. This is a form of “serverless” or on-the-fly data access. For instance, a nightly on-prem job could use DuckDB to pull some metrics from a cloud data lake table. The Iceberg abstraction makes the remote data appear as a regular SQL table.
Still Read-Only (for Now): The current DuckDB Iceberg integration is focused on reading tables. The preview is experimental and does not yet support writing back to Iceberg. In practice, this is not a huge limitation – writes are typically handled by heavier ETL processes (Spark/Flink) – and DuckDB can be used for fast querying and prototyping. The DuckDB team has indicated that a fully stable release will come later in 2025, likely with more features.
Overall, the DuckDB-Iceberg integration exemplifies the openness of Iceberg: even an in-process database can join the party of engines working on the same data. It underscores the trend of convergence between analytics tools – cloud data in Iceberg format can be accessed by cloud data warehouses, big data engines, and now even local analytics libraries. This flexibility is exactly what modern data architectures are aiming for.
Building a Lakehouse with Iceberg: Cloud and Hybrid Patterns
Apache Iceberg is a cornerstone of the data lakehouse architecture. A lakehouse typically consists of a unified storage layer (like a data lake on cloud storage or HDFS) with an open table format, and multiple compute engines for different workloads (ETL, ad-hoc SQL, machine learning, etc.). Iceberg enables this by acting as the table format and governance layer on the storage, ensuring all engines see consistent data. Let’s explore some ideal technology combinations for lakehouse and analytics use cases, in both cloud and hybrid environments:
Storage Layer: In a modern lakehouse, the storage is often cheap, scalable cloud object storage (e.g. Amazon S3, Google Cloud Storage, Azure Data Lake Storage) or a distributed filesystem (HDFS) for on-prem. Iceberg sits on top of this storage, managing files (typically in Parquet/ORC format) and tracking metadata. The Iceberg catalog (backed by Hive Metastore, AWS Glue, a REST service, etc.) serves as the source of truth for table definitions and snapshots.
Compute Engines: With Iceberg in place, you can mix and match engines, each specialized for a purpose:
Batch ETL and Processing: Apache Spark is commonly used for heavy batch transformations. For example, Spark jobs can read raw data, join and aggregate, and then write the results into an Iceberg table (on S3 or HDFS) as the sink. Iceberg’s format ensures each Spark job’s output is atomically added as a new snapshot. Other engines like Flink or SQL-based ELT tools can also produce data into Iceberg. The key is that the ingest engine can be chosen freely – as long as it speaks Iceberg, it can write to the lakehouse.
Interactive SQL and BI: For analytics and BI queries, a SQL query engine like Trino (Presto) is often layered on top. Trino has a native Iceberg connector, so it can query the tables Spark produced, with full support for partition pruning, filtering, even updates and deletes. Because Iceberg tracks precise data file stats, engines like Trino can perform interactive queries efficiently on huge datasets. Even cloud data warehouses like Snowflake or BigQuery can play this role by querying the Iceberg tables (more on that later). The benefit is that business analysts or tools (Tableau, etc.) can run fast queries on the latest data in the lake without moving it to a separate warehouse.
Data Science/ML Access: For machine learning model training or data exploration, teams might use Python or R environments. Instead of extracting data from a warehouse, they can directly load features or training sets from the Iceberg tables – either via DuckDB (as discussed) or Spark/PySpark, etc. This ensures that everyone (analytics or ML) is working off the same single source of truth on the lake.
Cloud-Native Lakehouse Example (AWS): Imagine a stack on AWS – data is stored in Amazon S3, and Iceberg tables are tracked in AWS Glue Catalog (or the new AWS “S3 Tables” service). Apache Spark on EMR might perform nightly batch ETL, writing data to these Iceberg tables. Analysts then use Trino (Athena) to run SQL queries directly on those Iceberg tables for interactive analysis. Because Iceberg is ACID, the Athena users never see partial writes; they only query committed snapshots. If needed, a Redshift Spectrum or Snowflake external table could also query the same data in S3. In this setup, S3 + Iceberg acts like the “data lakehouse” storage, and multiple query engines coexist on it. This provides warehouse-like capabilities (SQL, transactions) without all data having to reside inside a single proprietary warehouse, offering flexibility and cost advantages.
Hybrid Scenario: One of Iceberg’s strengths is in hybrid cloud environments. For instance, consider a company that has on-premises data centers and also uses cloud analytics services. They could keep an Iceberg table’s data in an on-prem HDFS cluster, but use a shared catalog so that cloud engines can also access it. Tools like Apache Hive or Spark on-prem might produce the data, but then a cloud service like Google BigQuery (via BigLake) or Snowflake can query that same table remotely. Because the Iceberg catalog is the authority, even across environments, everyone sees the same schema and snapshots. LinkedIn provides a real-world example: they ingest streams from Kafka and Oracle into Hadoop, writing data into HDFS in ORC format managed by Iceberg. Iceberg’s metadata gives them snapshot isolation and incremental processing for downstream consumers on that data. This means LinkedIn’s various pipelines (even outside of Hadoop) can consume the data gradually as new snapshots appear, without confusion or conflict. In general, Iceberg’s open format and catalog options (Hive, REST, etc.) enable data sharing across on-prem and cloud. A team can migrate or burst to cloud engines step by step, without migrating the entire dataset at once, since cloud and on-prem can both operate on the Iceberg table in parallel.
To summarize these patterns, we present a few typical Iceberg-based stack combinations and their benefits:
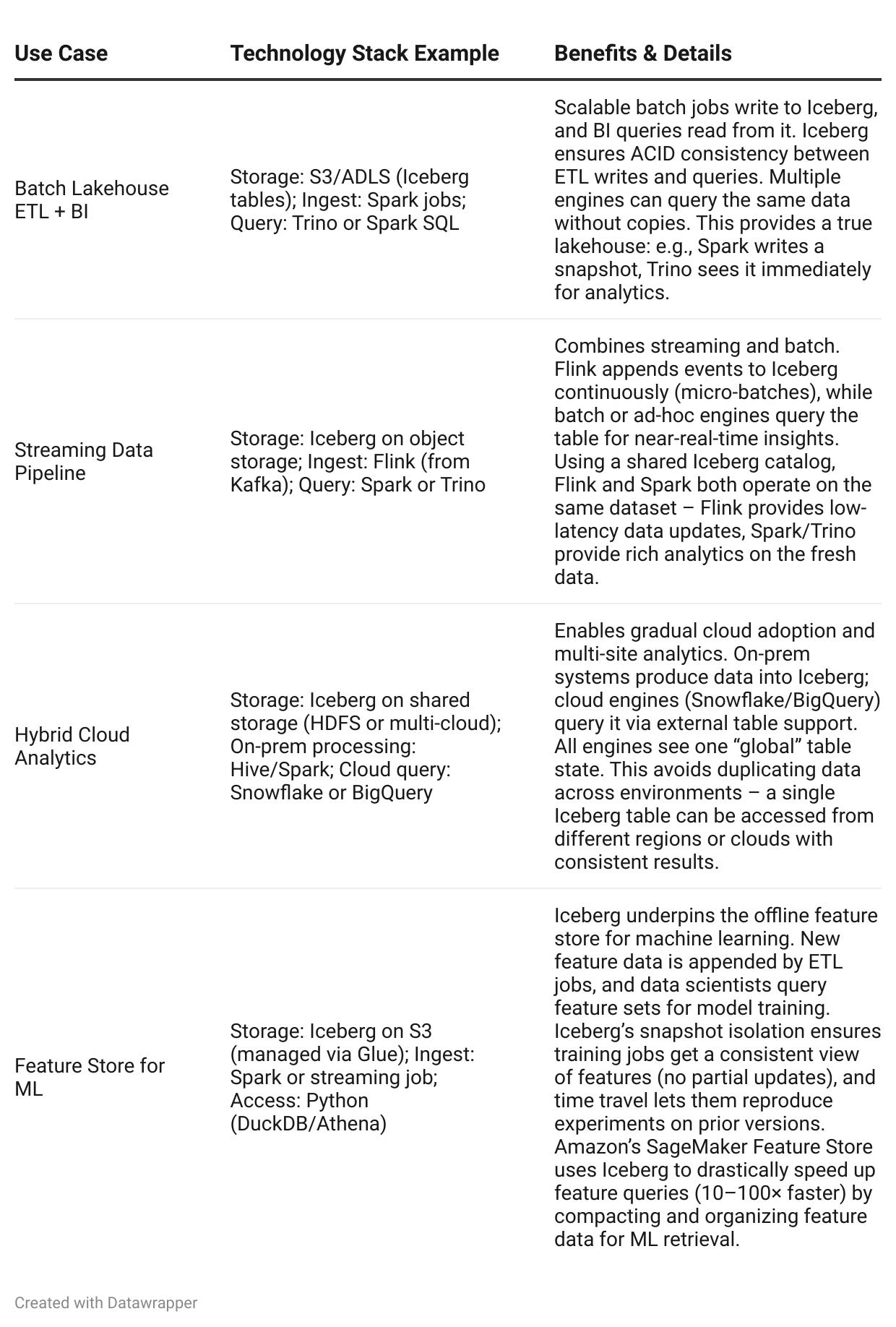
In all these scenarios, Iceberg provides the common table layer that knits the stack together. Whether it’s batch or streaming, cloud or on-prem, the decoupling of storage and compute that Iceberg enables is a game-changer. Data resides once (in open files), and many tools can use it in their own way – yet data governance, schema, and consistency are centrally maintained by Iceberg. This architecture is a key reason organizations are moving towards Iceberg-based lakehouses as a future-proof, flexible data infrastructure.
Streaming Data and Real-Time Analytics with Iceberg
Traditional data lakes were often batch-oriented, but Apache Iceberg also supports modern streaming and real-time data pipelines. By leveraging Iceberg’s design, we can build streaming systems that land data into analytical tables continuously, enabling up-to-date analytics without sacrificing consistency. There are a few dimensions to how Iceberg is used in streaming contexts:
Streaming Ingest (Write) into Iceberg: Tools like Apache Flink and Spark Structured Streaming can write to Iceberg tables in a streaming fashion. Rather than huge batch dumps, data can be ingested continuously into the Iceberg table as small batches or micro-streams. For example, Flink has an Iceberg sink connector that will periodically commit new data to the table (each commit becomes a new snapshot). This allows near real-time data to accumulate in the lakehouse. An important advantage of using Iceberg here is that even though data arrives continuously, each Flink commit is atomic – if you query the table, you either see the new batch entirely or not at all. Downstream jobs or analysts don’t see half-written data. This is crucial for data quality in streaming. It effectively brings the reliability of a database to a data stream landing in cloud storage.
Comparison to Direct Kafka Usage: Often, streaming architectures pipe data into Kafka for real-time and then later batch it into a lake. With Iceberg, some use cases can eliminate the extra queue: you can stream directly into an Iceberg table and treat that as both the source of truth and the serving layer for analytics. Steven Wu (an engineer at Apple) discussed how an “Iceberg streaming source” can power many common stream processing use cases, comparing it to using Kafka as a source. The takeaway is that while Kafka is great for ultra-low latency and pub/sub, Iceberg can serve in scenarios where a few seconds or minutes latency is acceptable in exchange for far simpler architecture and lower cost (since everything lands in the analytic store directly). Flink’s Iceberg integration is designed to allow incremental commits to Iceberg, meaning you can get latency in the order of seconds to a minute, yet have all the data neatly stored in Parquet files and immediately queryable by SQL engines.
Incremental Consumption (Read) from Iceberg: The flip side is reading Iceberg in a streaming manner. Iceberg’s table format supports incremental scan, where a processing engine can ask “give me all new data since snapshot X”. Apache Flink leverages this to create Iceberg source streams. In other words, Flink can treat an Iceberg table as if it were a continually updating source – each new snapshot in the table is like an event that Flink can capture and process further. This is a form of change data capture (CDC) or incremental ETL. For example, if one job is writing to an Iceberg table, another Flink job could monitor that table and immediately process new rows for downstream systems, achieving an end-to-end streaming pipeline entirely on Iceberg. This capability shows how Iceberg isn’t just for static datasets; it can be part of streaming architectures, acting almost like a message bus with storage.
Event Streaming + Iceberg in Tandem: Many real-world architectures combine event streams (Kafka, Kinesis) with Iceberg. A common pattern is: Kafka for immediate processing and low-latency data (seconds), and Iceberg for durable, queryable storage of events (minutes and beyond). Tools like Flink can read from Kafka, do some transformations, and continuously upsert into an Iceberg table. The Iceberg table then becomes a queryable history of the stream. This is very useful for late arrivals and backfills – things that are hard to manage in a pure event stream can be naturally handled in Iceberg (since you can always write a correction record or compact data in Iceberg). Netflix’s use case aligns with this: they built an incremental processing solution where data flows through their stream processing (Maestro workflow) into Iceberg, which provides a scalable way to do backfills and guarantee accuracy without reprocessing everything from scratch.
Real-Time Analytics: Once streaming data lands in Iceberg, it opens the door for real-time analytics on the lakehouse. For instance, you might have a dashboard running Presto/Trino queries on an Iceberg table that is updated by Flink every few minutes. You get “near-real-time BI” without a separate real-time database. Iceberg ensures that each query sees a consistent snapshot. If the dashboard is set to refresh every 5 minutes, and Flink commits new data every minute, the viewers will always see a point-in-time consistent view. They might be, say, one minute behind the latest data – often an acceptable trade-off.
Another emerging concept is using Iceberg as a materialized view or serving layer for streams. Because Iceberg can organize data by time and partition, a well-designed Iceberg table can serve both recent data fast and also provide the historical depth. Companies like Confluent (with Kafka and Flink) talk about leveraging Iceberg to unify streaming and batch views of data. Instead of maintaining both a real-time store and a separate batch store, Iceberg can act as the singular store that is continuously updated (sometimes this approach is called a “unified log” or Lakehouse with streaming).
Latency and Considerations: It’s important to note that Iceberg-based streaming typically has slightly higher latency than pure event streaming (due to the time to buffer and create file commits). However, it greatly simplifies architectures for many analytics use cases that don’t require sub-second latency. It’s a more cost-efficient approach for high throughput streams where storing long histories in Kafka would be expensive. By using Iceberg, all that data is immediately available for SQL queries and ML, which is not true for raw event logs.
In summary, Iceberg extends its usefulness to streaming scenarios by providing a framework to ingest, store, and consume continuous data with the same robustness as batch data. This convergence of streaming and batch in the lakehouse is a powerful concept: one platform for both real-time and historical analytics. As tooling (like Flink, Spark streaming, Kafka Connect, etc.) continues to improve around Iceberg, we can expect more and more “real-time lakehouse” deployments in production.
Integration with Other Key Technologies and Engines
Apache Iceberg’s success is largely due to its broad ecosystem integration. It is not a standalone system; it works in concert with many engines and platforms. Here we provide in-depth information on how several key technologies integrate with Iceberg and what capabilities each combination offers:
Apache Spark
Apache Spark was one of the first engines to integrate with Iceberg (indeed, Iceberg was born out of Netflix’s use of Spark with petabyte datasets). Spark provides an Iceberg connector (available as a package iceberg-spark for Spark 3.x) that allows Spark SQL and DataFrame APIs to read and write Iceberg tables natively. This means you can do spark.read.format("iceberg").load("db.table") to load an Iceberg table into a DataFrame, or write DataFrames out to Iceberg with full support for partitioning, schema, etc. Spark + Iceberg offers a powerful combination:
ETL and Batch Writes: Spark is commonly used to perform large-scale ETL into Iceberg. It can create or replace entire partitions, or append new data, using Iceberg’s API to commit changes. Because Iceberg ensures atomic commits, multiple Spark jobs can safely write to different tables (or even the same table in some cases with proper isolation) without interfering.
SQL Support: Spark SQL understands Iceberg tables as first-class citizens. One can write SQL to query Iceberg tables (Spark will push down predicates to Iceberg for file pruning). Spark 3 even supports DML operations on Iceberg tables: you can MERGE INTO, UPDATE or DELETE from an Iceberg table using standard ANSI SQL syntax, and Spark will translate that into Iceberg’s procedures (creating new data files and delete files under the hood). This brings data warehouse-like data management directly to your data lake.
Streaming Reads/Writes: Spark Structured Streaming can read from an Iceberg table as a source (treating new snapshots as increments) and also write to Iceberg as a sink. This isn’t as real-time as Flink typically, but it allows Spark to be part of streaming pipelines with Iceberg.
Use in Databricks: Notably, Databricks (the company behind Delta Lake) has also added support for Iceberg in its platform. This means on a Databricks cluster you could choose to use Iceberg instead of Delta for certain tables. Databricks has even open-sourced some adaptors to ensure their runtime works efficiently with Iceberg. This is a testament to Iceberg’s popularity – even a would-be competitor like Databricks is embracing it because customers use it.
Migration of Hive Tables: A big use case for Spark + Iceberg is migrating legacy Hive tables into Iceberg format. Spark has utilities to snapshot existing Parquet datasets into Iceberg without data copy. Once under Iceberg, the old Hive table’s issues (like too many partitions) disappear. Many companies (as noted earlier) have done exactly this to solve Hive metastore bottlenecks.
In short, Spark serves as both a producer and consumer in the Iceberg ecosystem. It brings the muscle for heavy data lifting, and Iceberg ensures those outputs are accessible beyond Spark.
Trino / Presto
Trino (formerly PrestoSQL) is a distributed SQL query engine often used for interactive analytics and BI dashboards. Trino has a well-developed Iceberg connector which allows it to query (and modify) Iceberg tables as if they were tables in a database. Key points about Trino + Iceberg:
Interactive Analytics: Trino is designed for low-latency SQL on large data. With Iceberg, Trino can perform interactive queries even on huge datasets because Iceberg’s metadata helps Trino skip reading a lot of unnecessary data. For example, Trino will use Iceberg’s partition stats and file stats to only read relevant files for a given query, making scans much faster than if it had to brute-force read all files. One blog noted that many engines including Trino have done significant work to optimize Iceberg queries, indicating the performance can be very high.
DML and Transactions: Trino’s Iceberg connector supports not just SELECTs but also INSERT, UPDATE, DELETE, and MERGE operations on Iceberg tables (assuming the Trino cluster has the correct privileges and is configured with an Iceberg catalog). Underneath, each such operation becomes a transactional commit in Iceberg. This means you could use Trino to do data cleaning (e.g. “DELETE FROM table WHERE bad_field IS NULL”) and it would actually rewrite or remove data files in the Iceberg table, following Iceberg’s format. Such capabilities were not possible with older Hive tables in Presto – it’s the Iceberg layer that makes it possible to mutate data reliably.
Multiple Catalogs: Trino can be configured to use various Iceberg catalogs. For example, you might configure one catalog that points to an HDFS-based warehouse (with a Hive Metastore), and another that points to an S3-based Iceberg warehouse (with Glue). This flexibility allows querying Iceberg tables across environments in one Trino query. Trino doesn’t care where the data is – it only needs the Iceberg API and the underlying file access.
Concurrent Use with Other Engines: Because Trino is often a read-heavy engine and Spark is write-heavy, a common pattern is Spark produces data into Iceberg, and Trino serves it to analysts. They coordinate through the Iceberg catalog. As soon as Spark commits a snapshot, Trino queries will see the new data on the next snapshot refresh. If a query is mid-flight, it uses the last snapshot; the next query will use the new one. This ensures readers (Trino) and writers (Spark) don’t conflict – a form of multi-engine concurrency which Iceberg enables by design.
Trino is increasingly used as the SQL interface for the lakehouse in many companies, and Iceberg is a natural fit for it. The combination provides a feel of a “database” (Trino + Iceberg) that is actually running over open files.
(Note: PrestoDB, the Facebook-led fork of Presto, also has an Iceberg connector. However, most of the community and new features are in Trino, so we focus on Trino.)
Apache Flink
Apache Flink is a powerful stream processing engine, and its integration with Iceberg positions Iceberg as a bridge between streaming data and batch analytics. Flink’s Iceberg integration includes:
Iceberg Sink: Flink can write data into Iceberg tables in real-time. This sink is designed to batch up small events into parquet files and commit them on the fly. It uses the Iceberg API to commit snapshots, so each Flink checkpoint can correspond to an Iceberg commit. This allows exactly-once delivery semantics from Flink into Iceberg (with careful configuration). Many folks use this to ingest data from Kafka into Iceberg continuously, as mentioned earlier. A nice feature is that Flink can also handle UPSERT streams into Iceberg (for tables with primary keys) by writing equality delete files and new rows, enabling slowly-changing data to be stored in Iceberg.
Iceberg Source: Flink can treat an Iceberg table as a source of streaming data. Internally, this means Flink will periodically check the table for new snapshots and emit new rows or changes. This effectively makes the Iceberg table like a change log that Flink can further process. For example, if you have an Iceberg table that is being updated by some batch jobs, a Flink job could monitor it and index those updates into Elasticsearch, etc. This source is a newer capability (supported since Iceberg 0.11+ and Flink 1.14+); it uses Iceberg’s snapshot diff feature to only read the deltas.
Unified Pipeline (Batch + Stream): Flink is unique in that it can do batch and stream in one. With Iceberg, a Flink job could run in micro-batch mode, reading an Iceberg table, doing some aggregation, and writing the result out to another Iceberg table, all continuously. Because both source and sink are Iceberg, the entire pipeline benefits from schema evolution, time travel (for reprocessing old data if needed), and no separate staging storage. This greatly simplifies architectures for complex data transformations that need to run 24/7.
Integration in Confluent Platform: Confluent (known for Kafka) has been investing in Flink and mentioned “Tableflow” in some contexts – essentially using Flink+Iceberg to integrate streaming with table storage. This indicates how streaming vendors see Iceberg as important. By using Flink and Iceberg together, one can implement the concept of data as a continually updating table rather than an unbounded event log, which is a more query-friendly format for many users.
In practice, Flink + Iceberg is a popular choice for real-time data lakes. Companies like Apple, for example, have engineers (like Steven Wu in the talk) working on these integrations for their AI/ML platforms. Alibaba contributed heavily to Flink-Iceberg integration as well (for their cloud). If Spark is the king of batch on Iceberg, Flink is becoming the king of streaming on Iceberg.
Snowflake
Snowflake is a cloud data warehouse that traditionally kept data in its own proprietary storage format. But Snowflake now supports Apache Iceberg tables in a feature they sometimes call “Iceberg Tables” in Snowflake. This integration is significant because it blends the lines between data warehouse and data lake. Here’s how it works:
External Iceberg Tables: Snowflake can query Iceberg tables that live outside of Snowflake. The data (Parquet files and Iceberg metadata) might be in an S3 bucket that Snowflake has access to. Using an External Volume (Snowflake object) to connect to the cloud storage, Snowflake can treat an Iceberg table almost like one of its own. The Iceberg catalog can be external (like AWS Glue) or Snowflake can be configured to manage the Iceberg metadata itself. In both cases, Snowflake’s compute engine will read the Parquet files directly and use Iceberg metadata for partition pruning, etc. The benefit here is that Snowflake users can join Iceberg data with their internal tables in one query. And importantly, Snowflake does not charge storage for Iceberg tables (since Snowflake isn’t storing the data) – you only pay Snowflake for compute when querying, making it an attractive option to bring your own Iceberg data.
Snowflake-managed Iceberg Tables: Snowflake also introduced the ability to create a table in Snowflake that is actually stored as Iceberg in your cloud storage. In this scenario, Snowflake itself can act as the Iceberg catalog. So when you do CREATE TABLE ... USING ICEBERG in Snowflake, it might create the metadata in its own services but the data files in your S3. This gives you the best of both worlds – Snowflake’s high-performance engine and services like automatic clustering, plus data that’s in open format you can also access outside of Snowflake if needed.
Functionality: Snowflake supports schema evolution and other Iceberg features on these tables. You can use Snowflake SQL to insert or update Iceberg tables. Under the hood Snowflake will generate Parquet files and update the Iceberg metadata (it’s effectively acting as an Iceberg-compatible writer). Snowflake ensures these operations are transactionally consistent via Iceberg’s atomic commit design. One limitation is that currently Snowflake’s Iceberg tables are often read-only to other engines while Snowflake is writing unless using an external catalog integration. Snowflake has something called Snowflake Open Catalog which can sync Snowflake-managed Iceberg metadata out so that outside engines (like Spark) could see it. This is evolving, but it highlights a key point: Snowflake is treating Iceberg as a first-class citizen.
Cross-cloud and Hybrid: A really interesting aspect is cross-cloud querying. Because Iceberg keeps data in e.g. S3, Snowflake (which runs in AWS, Azure, GCP) can attach to an Iceberg table even if the table is stored in another cloud or region, as long as network access is in place. This decoupling can help avoid silos. For example, a Snowflake user in Azure can query an Iceberg table stored on AWS S3. Traditionally that’s hard to do without moving data. Iceberg (plus Snowflake’s external volume concept) makes it feasible.
Why use Snowflake with Iceberg? One might do this to use Snowflake’s smooth managed service and powerful optimizer on existing data lake files. It can be a bridge for organizations that have a foot in the open data lake world and a foot in the warehouse world. It also shows the confidence Snowflake has in Iceberg as a stable format. Snowflake’s documentation and updates indicate they are regularly adding new Iceberg features, meaning over time the gap between what Snowflake can do with its internal tables versus Iceberg tables is closing.
Google BigQuery
Google BigQuery has similarly embraced Iceberg, primarily through its BigLake initiative. BigLake is a capability that allows BigQuery (and other Google Cloud services) to treat external data on cloud storage with governance and performance optimizations. Iceberg is one of the formats supported:
BigLake External Tables for Iceberg: BigQuery can create an external table pointing to an Iceberg table on Google Cloud Storage (GCS). This is read-only access – BigQuery will query the data via the Iceberg metadata, but not write to it. BigQuery applies its security and fine-grained access control on these external tables, integrating with GCP’s unified controls. The performance is improved over naive external queries because BigQuery can use Iceberg’s partition pruning and maybe pushdown filters (though BigQuery may still need to spin up some execution to read the Parquet files). This allows federated querying, where BigQuery SQL can combine data from Iceberg tables and native BigQuery tables.
BigQuery Iceberg Tables (Managed): In 2025, Google announced BigQuery support for Iceberg Metastore functionality. Essentially, Google introduced a BigQuery Metastore that is Iceberg-compatible, aiming to unify metadata across engines. BigQuery can actually manage Iceberg tables natively – sometimes referred to as “BigQuery managed Iceberg tables”. These are similar to Snowflake’s managed approach: data in GCS, but BigQuery can update it and track it. The BigQuery metastore is a fully managed service where you can register Iceberg tables, and it ensures that engines like Spark or Flink can interoperate with BigQuery on the same data. The motivation, as Google described, is to avoid the scenario of multiple metastores (Hive, etc.) with inconsistent definitions when you use multiple engines. With a unified Iceberg metastore, BigQuery wants to let you query one copy of data with a single schema, whether using BigQuery or Spark or Flink.
BigQuery + Dataproc (Spark): Google’s Dataproc is basically managed Spark/Flint/Hive on GCP. Dataproc has Iceberg packages too. With the new BigQuery metastore, a Spark running on Dataproc can use the same Iceberg table as a BigQuery SQL query, and the metadata doesn’t need duplication – they both talk to the BigQuery Iceberg catalog. This scenario is a classic lakehouse: Spark might write data, BigQuery reads it, or vice versa, with full consistency. It’s essentially Google’s version of the lakehouse using Iceberg under the hood.
The bottom line is Google acknowledges the need for open formats. Rather than only using BigQuery’s native storage (which is proprietary), they’re giving customers the option to use Iceberg to enable multi-engine flexibility. This is attractive for hybrid scenarios too: e.g., on-prem Spark jobs could produce Iceberg data, which BigQuery in GCP can then analyze, facilitating cloud adoption.
Other Engines and Tools
Beyond the above, there are other notable integrations:
Apache Hive: Iceberg has a Hive runtime module that lets Hive read Iceberg tables (Hive treats it kind of like an external table). However, Hive’s slow development and the rise of newer engines mean this is less commonly used except for legacy compatibility.
Apache Impala / Cloudera: Cloudera’s platform (CDP) has added support for Iceberg in Impala and Hive LLAP. Cloudera, as noted, embraced Iceberg (as well as Hudi) to give its customers modern table format options. So Impala, a traditional MPP SQL-on-Hadoop engine, can query Iceberg tables, use Iceberg’s metadata for performance, etc. This allows Cloudera users (on-prem enterprise Hadoop) to also enjoy Iceberg’s benefits without bringing in new engines.
Dremio: Dremio is a SQL engine and data platform that heavily uses Apache Arrow. Dremio has been a big proponent of Iceberg – they even created a managed Iceberg catalog service called Arctic. Dremio’s query engine can read Iceberg tables and they integrate features like reflection (caching) with Iceberg metadata. Essentially, Dremio provides a BI-friendly layer over Iceberg and has contributed improvements to the project.
AWS Athena: Athena is Amazon’s Trino-based serverless query service. Athena added support for Iceberg as one of its table formats (in addition to Hive, Hudi, etc.). Athena uses the AWS Glue Data Catalog, which now can store Iceberg table metadata. This means Athena users can create Iceberg tables and query them with Athena’s SQL. The benefit is more functionality (updates, time travel via Athena console by specifying a snapshot ID, etc.) over plain Hive tables, and better performance on partition-heavy data.
Redshift Spectrum: Redshift’s external querying feature likely can work with Iceberg tables registered in Glue as well, though Amazon more actively pushes Athena or their new S3 Tables approach for Iceberg.
Query Federation Tools: There are tools like Starburst Galaxy (Trino SaaS) which provide an out-of-the-box Iceberg catalog and maintenance automation, and open source projects like Nessie which serve as an advanced Iceberg catalog with Git-like version control (we’ll discuss in ecosystem). These are part of the integration landscape making Iceberg easier to use in various contexts.
The common theme is ubiquity: virtually any tool that deals with analytic data either already supports Iceberg or is in the process of doing so. This broad compatibility is what makes Iceberg so powerful in a modern stack – you aren’t limited to one framework’s capabilities. Each engine integrates in its own way but adheres to the Iceberg spec, allowing a seamless flow of data across them.
Tooling Ecosystem and Adoption in AI/ML Workflows
Beyond engines and query platforms, Apache Iceberg benefits from a growing ecosystem of catalogs, management tools, and adoption by forward-looking organizations. This ecosystem is crucial, especially as companies deploy Iceberg in support of AI and machine learning workflows that demand both flexibility and control over data.
Catalog and Metadata Tools
The Iceberg catalog is a pluggable component – it stores the mapping of table names to metadata files and coordinates atomic changes. Several options exist:
Hive Metastore: Many use Hive Metastore as a basic catalog (especially in on-prem or older environments). It stores the pointer to the Iceberg table’s latest metadata file. This works but Hive Metastore has scaling limits and lacks advanced features.
AWS Glue Catalog: On AWS, Glue is a drop-in replacement for Hive Metastore (fully managed). Glue now supports Iceberg table types. It is commonly used for Iceberg catalogs in AWS (Athena, EMR, etc.). Glue is more scalable and integrated with AWS IAM security.
Nessie: Project Nessie is an open source metadata service designed for Iceberg (and Delta/Hudi). It introduces Git-like version control for data. With Nessie, you can have multiple named branches of an Iceberg table, tag snapshots, and merge changes. This is incredibly useful for ML and data experimentation – e.g., a data scientist can create a branch of the table, do some test writes or backfills, and if all looks good, merge to main, or discard if not. Nessie essentially serves as a modern catalog “control plane” for Iceberg. Dremio’s Arctic offering is built on Nessie, providing a cloud service where you get those capabilities plus nice UI. This kind of tooling is important for AI/ML, where you might want to maintain training datasets in different branches (say “production data” vs “experimentation data”) and ensure reproducibility.
Iceberg REST Catalog: The Iceberg community defined a REST API for catalogs, which allows a lightweight service to host table metadata. Companies like Tabular (founded by Iceberg’s creators) offer a hosted REST catalog. AWS’s new S3 Table service also implements the REST catalog API. The advantage is simplicity and uniform access (the client doesn’t need a heavy Hive/Glue dependency, just HTTP). DuckDB’s integration, as mentioned, uses the REST catalog API to attach to AWS Glue or S3 Tables endpoints. This trend points to more cloud-native ways to manage Iceberg metadata that fit well with serverless and polyglot environments.
Polaris/Atlan: Some data catalog companies (like Atlan with their Polaris) are integrating with Iceberg to provide governance, search, and lineage on Iceberg tables. Because Iceberg keeps a history of snapshots, it is fertile ground for building lineage tools and audit trails. We see cloud providers and startups building catalogs that treat Iceberg as the heart of the data lakehouse, adding on governance features like data masking, role-based access, and search over schema/data.
In essence, a rich catalog layer is emerging around Iceberg, which is extremely important for AI/ML as these fields demand data versioning, reproducibility, and experiment tracking. The fact that Iceberg has built-in versioning and tracks all changes makes it much easier to integrate with experiment tracking systems (like one could store the snapshot ID used for a particular ML model training run, and later reconciling what data was used is straightforward).
Data Ingestion and Transformation Tools
Various tools in the data pipeline space have added support for Iceberg:
Kafka Connect: There are connectors that can sink data from Kafka topics into Iceberg tables (Confluent and others have released such connectors). This automates streaming ingest without needing a full Flink deployment.
Apache NiFi / StreamSets: Some ETL tools can now write to Iceberg as a destination, making it easier to onboard data.
dbt (Data Build Tool): dbt, a popular analytics engineering tool, doesn’t directly interact with file tables, but it can run SQL against engines that do. So if one uses Trino or SparkSQL with Iceberg, dbt models can be built on Iceberg tables just like they would on a Snowflake table. This allows analytics teams to use familiar workflows (version-controlled SQL transformations) directly on the lakehouse data.
Compaction and Maintenance: Over time, Iceberg tables may need maintenance (expiring old snapshots to free space, compacting small files, etc.). Tools to do this include built-in Spark actions (the Iceberg API provides procedures for expiring snapshots, rolling up manifests, etc.), standalone utilities, and features in managed offerings (e.g., Starburst’s platform can automatically compact Iceberg small files in the background). Proper tooling here is important to keep performance optimal (particularly for streaming ingest use cases that create many small files). As the ecosystem matures, we see more automated solutions to handle this, reducing the manual burden on data engineers.
Adoption by Major Organizations (especially in AI/ML contexts)
Apache Iceberg has seen widespread adoption at some of the largest data-driven companies, many of whom explicitly mention its use in AI and ML workflows:
Netflix – Netflix created Iceberg to solve their big data challenges. It remains core to their data platform. Netflix has an end-to-end pipeline platform (called Maestro) and they combined it with Iceberg to handle incremental data processing with guaranteed accuracy. For ML, this means new training data can be backfilled or updated incrementally without confusion. Thousands of Netflix data users (analysts, data scientists) rely on Iceberg daily as the storage layer for data ranging from streaming metrics to content personalization data.
Apple – Apple’s AIML (AI & Machine Learning) data platform team is heavily invested in Iceberg. Apple has spoken about building streaming pipelines with Flink and Iceberg to support things like Siri and iCloud analytics. When a tech giant like Apple with massive ML workloads (think Siri’s natural language models, personalization across devices, etc.) uses Iceberg, it indicates that Iceberg can handle extreme scale and strict data quality requirements.
LinkedIn – LinkedIn uses Iceberg in their Hadoop-based data lake to reduce latency and improve reliability of ingestion for their analytical datasets. One specific use: Gobblin, LinkedIn’s ingestion framework, writes to Iceberg to ensure that downstream jobs see a consistent view of new data. By using Iceberg, LinkedIn achieved lower latency from Kafka into HDFS (because they no longer needed to create ad-hoc Hive partitions or many small files). For ML, LinkedIn can incrementally update feature tables and immediately have those features available for model scoring or training in a consistent way.
Adobe – Adobe Analytics and the Adobe Experience Cloud handle billions of web events and user data points for personalization and marketing analytics. Adobe adopted Iceberg to manage this firehose of event data and make it queryable for personalization algorithms. In practice, Iceberg helped Adobe ensure data consistency at scale and simplified their data engineering for user profiles (which power ML-driven personalization). Adobe has demonstrated how they can replay and time-travel on user event data to test new ML models against historical data, thanks to Iceberg’s snapshot abilities.
Airbnb – Airbnb moved from a heavy Hive-on-HDFS infrastructure to Iceberg on S3 to support their data warehousing needs. They faced Hive Metastore overload and slow partitioning, which Iceberg solved\. Now, Airbnb analysts and ML pipelines (e.g. price optimization models, search ranking models) operate on Iceberg tables in S3. They have noted significantly reduced engineering overhead once on Iceberg – no more maintaining two sets of tables for different time granularities, etc., because Iceberg handles it gracefully.
Stripe – Stripe processes financial transaction data and needs strong consistency. Stripe has been cited as a contributor to Iceberg. It’s likely used in their analytical platform for fraud detection features, which are ML-driven and require combining historical and real-time data under stringent correctness.
Expedia – Expedia contributed to Iceberg as well. They likely use it for their travel data platform – imagine training ML models to recommend hotels or optimize pricing, on top of an Iceberg-backed feature store that contains years of travel booking data combined with fresh user search events.
TikTok (ByteDance) – Although not listed in sources above, there was a mention of a YouTube talk about building an exabyte-scale feature store at ByteDance with Iceberg. ByteDance (TikTok’s parent) handles enormous volumes of video engagement data and uses ML for recommendation. An Iceberg-based feature store at exabyte scale underscores how well Iceberg can scale and serve ML: it can deliver the throughput needed and maintain data versions for model training at one of the world’s largest social media data scales.
This is just a sample; the list of companies using Iceberg reads like a who’s who of data innovation. Importantly, many of these organizations explicitly mention AI/ML use cases alongside analytics. The ability to share one data foundation between AI and BI is a huge win. Iceberg’s features like time travel allow ML engineers to train models on yesterday’s data and then easily compare with models trained on today’s data. Its schema evolution means adding a new feature column is straightforward and doesn’t break older pipelines – vital for iterative ML experimentation. Also, consistency guarantees mean that a model never trains on partial data from a broken pipeline; it either gets a full snapshot or none.
Community and Contributors: Companies such as Netflix and Apple contribute code; tabular.io (the startup by creators) drives community efforts; Cloudera, Dremio, AWS, and others contribute as well. This broad contributor base (Netflix, Apple, Airbnb, Expedia, LinkedIn, Alibaba, Tencent, AWS, etc.) means Iceberg is not controlled by a single vendor, unlike some alternatives. That has reassured many users and spurred adoption – they see Iceberg as a truly open project with a long future.
AI/ML Workflow Benefits Recap
To highlight why Iceberg is great for AI/ML workflows (tying together the tools and adoption):
Feature Store Offload: Many feature stores (like SageMaker Feature Store, Feast, etc.) use Iceberg as the offline store. As mentioned, SageMaker saw up to 100x speedups on feature queries with Iceberg due to file compaction and efficient pruning. This leads to faster model training iterations.
Experiment Reproducibility: By tagging snapshots or using branches, data scientists can recall exactly what data a model was trained on (fixing the “versioning the data” problem in ML). Iceberg’s snapshot IDs act as data version identifiers.
Data Lineage for ML: Tools like Nessie allow branching, which can isolate “experimental data” from “production data” for ML. Also, if a new data processing logic is tested, you can write to a branch, validate model results, then merge.
High Throughput for Big Data: AI often means big data (e.g., training a deep learning model on a huge dataset). Iceberg can feed these pipelines with throughput comparable to raw Parquet, because under the hood it is Parquet/ORC. The overhead of Iceberg’s metadata is negligible during large sequential reads – and it may even make things faster by skipping files. Thus ML pipelines (e.g., Spark ML jobs or TensorFlow reading from Petastorm which could use Iceberg) get both performance and reliability.
Unified Batch and Real-Time Features: An emerging ML challenge is unifying batch and real-time feature engineering. Iceberg can store both historical features and be updated in near-real-time with new feature values (via streaming ingest). So one system can serve for training (which needs full history) and for near-real-time scoring (where new data comes in continually). This unity prevents training/serving skew.
All these benefits are driving organizations with heavy ML investments to adopt Iceberg as a foundational layer. It’s not just a better “data table” – it’s enabling new, efficient ways to do data science on lakes
Architecture and Performance: How Iceberg and Its Tools Work Together
Apache Iceberg’s architecture underpins everything discussed so far, so we conclude with a summary of how Iceberg achieves these capabilities and integrates all the tools:
Layered Architecture: Iceberg’s table format is built in layers – catalog, metadata, and data layers – which cleanly separate concerns:
The Catalog layer stores the table’s current metadata pointer (and namespace of tables). This is like a lightweight metastore or “name service.” When a writer commits a new snapshot, it atomically updates this pointer in the catalog. When a reader opens the table, it retrieves the pointer to find the latest metadata. This design allows multiple engines to share the table easily: Spark, Flink, Trino, etc. all talk to the same catalog and thus agree on what the “current” snapshot of the table is. The catalog ensures operations like table creation, drop, rename, snapshot switch are atomic and consistent across all clients.
The Metadata layer is where Iceberg really innovates for performance. The main object is the metadata file (JSON format) which lists table schema, partition spec, and references to snapshot information. Each time data changes, a new metadata file is written. The metadata file contains pointers to one or more manifest lists (one per snapshot). A manifest list is essentially an index of all manifests that comprise that snapshot. Each manifest file in turn contains a list of data files and associated stats (min/max values, record count, etc.). This hierarchical design means that to plan a query, an engine can read just a few files: the metadata file (small JSON), one manifest list (small), and then only the manifest files relevant to the query (Iceberg will let the engine filter manifests by partition or other stats before reading them). This avoids ever having to touch the raw file system or list directories. For example, a table with 10,000 data files might be tracked by 10 manifest files (each listing ~1000 files). To find the subset for a query on one partition, maybe only 1 of those manifest files needs to be read – result: only 1000 file entries are scanned instead of 10,000, a big win. This is how Iceberg achieves advanced pruning and planning and makes queries on large data more efficient. The metadata layer also stores extra goodies like statistics and bloom filters that engines can use to skip even inside files.
The Data layer is the actual data files – usually Parquet, ORC, or Avro files with the table’s columns. These are stored in the lake (S3, HDFS, etc.). Iceberg does not change the file format; it leverages the highly optimized columnar formats. Thus, once an engine decides to read a particular data file, it uses the normal Parquet/ORC reader – benefiting from vectorized IO, predicate pushdown, column pruning, compression, etc. This means that Iceberg’s presence adds essentially zero overhead to the actual scan – if anything, it reduced overhead by eliminating needless file opens. In practice, query performance on an Iceberg table vs. the same data in raw Parquet files is equal or better, because Iceberg optimizes the planning phase heavily.
ACID and Multi-Engine Operation: When a writer (say Spark) wants to commit data:
It writes new data files (e.g., Parquet files) to the storage.
It creates new manifest files that list those data files (and perhaps mark some old ones for deletion if it’s doing an update).
It writes a new manifest list for the snapshot, and a new metadata JSON pointing to that snapshot.
Finally, it asks the catalog to atomically update the table’s pointer to the new metadata file.
This final step is where ACID magic happens: Iceberg uses atomic operations (like Glue’s transaction, Hive metastore’s lock, or a lightweight DB transaction in case of a REST catalog) to ensure only one writer’s metadata becomes “current”. If two jobs try to commit, one will succeed, the other will detect the conflict and can retry (using snapshot conflict detection). This optimistic concurrency model is similar to Git – if there’s a conflict, you rebase and retry commit. The outcome is multiple writers across different engines can reliably commit to the same table without corrupting it. This was impossible in the old Hive world. Iceberg’s design guarantees consistency: readers either see the old snapshot or the new one, never a mix. So, engines like Trino or Flink polling the catalog will just start reading the new snapshot once available. They don’t need a complex locking coordination with Spark – Iceberg did the heavy lifting via the metadata atomic swap.
From an architecture integration standpoint, this means each engine (Spark, Flink, etc.) just needs to implement the Iceberg API to read/write those metadata and data files. They don’t implement ACID themselves; they delegate to Iceberg. This made it relatively straightforward to add Iceberg support to engines – which is why we saw so many integrate it quickly. All engines speak the “Iceberg language” in metadata, so they naturally interoperate.
Performance Considerations: A few points:
Eliminating “Small Files” Problem: By not exposing file count to users and handling merges via metadata, Iceberg encourages practices like compacting small files and writing larger files, which dramatically improves scan performance on cloud storage. Many engines have built-in actions or queries to compact Iceberg table files (e.g., a Spark SQL procedure OPTIMIZE table or an Iceberg API action can rewrite small files into bigger ones). The result is faster reads and fewer I/O operations. Organizations have reported order-of-magnitude improvements in certain queries after migrating to Iceberg simply because they got rid of overhead like millions of tiny files or overloaded metastores.
Reduced Metadata Overhead: In large datasets, metadata operations (listing directories, opening thousands of file footers) can dominate query time. Iceberg’s manifest approach shrinks this overhead. For example, Netflix mentioned that with Iceberg, their metadata read time became a small fraction of total query time, whereas previously it was a big chunk (with Hive metastores struggling). As a quantitative example, if a query needs to scan 1 out of 1000 partitions, Iceberg will open maybe a couple of small files to find which data files to read, whereas a Hive approach might have to list and open hundreds of file system directories. This is a big win in cloud object stores which have non-trivial latency for list operations.
Predicate Pushdown and File Skipping: Iceberg stores min/max statistics for columns at the file level in manifests. So if a query has a filter like WHERE date = '2025-04-18', Iceberg can avoid any manifest (hence data files) that don’t include that date in their stats. This is on top of Parquet’s page-level stats – it’s a higher-level pruning. Engines like Spark and Trino leverage this for extra efficiency. It’s like partition pruning on steroids (since it’s not limited to just partition columns, it can use any column stats present).
Parallelism and Scale-Out: Iceberg is designed to work with distributed engines. The planning (reading manifest files) can itself be done in parallel by the engine (many engines will read manifests using multiple threads or tasks). Once the list of data files is known, they’re distributed among worker nodes to read. There is no single choke point in Iceberg – the metadata is stored distributed (many manifest files) so planning can scale. Some very large tables might have hundreds of manifest files per snapshot; reading them is embarrassingly parallel. This ensures that as your data grows, query planning doesn’t become a bottleneck.
Resource Footprint: The metadata files are typically small JSON and Avro files; memory overhead to hold the file list is moderate and controllable (Iceberg will split manifests to keep each a reasonable size). This means an engine can plan a huge table in constant memory by streaming through manifests. It won’t blow the driver heap, etc. It’s a subtle but important architectural point for stability.
Ecosystem Synergy: Because Iceberg handles the hard parts of metadata and atomicity, each tool in the ecosystem can focus on its strength (fast SQL execution, or stream processing, or UI, etc.) and rely on Iceberg for data correctness. This synergy is what we observed:
DuckDB could quickly add remote data querying because Iceberg presented a stable REST interface.
Snowflake and BigQuery could relatively easily incorporate Iceberg because they just consume the metadata and attach their compute; they didn’t have to reinvent the wheel for how to track table versions.
Tools like SageMaker Feature Store gained huge performance boosts by using Iceberg’s compaction and file tracking instead of a naive “dump files to S3” approach.
Streaming engines and batch engines coordinate implicitly: Flink writes to table -> Spark reads it -> Trino serves it, all orchestrated by Iceberg’s snapshot mechanism.
In effect, Apache Iceberg provides a common language of data that all these different systems speak. It abstracts the physical data layout and provides a consistent view and set of operations. This is why we often call Iceberg the data platform or data layer in a modern architecture.
To conclude, Iceberg’s architecture delivers reliability, openness, and performance at scale. Its careful design (inspired by lessons from big data’s first decade) removes previous inefficiencies (like the old Hive approach) and replaces them with robust, performant techniques. The result is a virtuous cycle: as more engines adopt Iceberg, it becomes more valuable, and as more organizations use it in novel ways, the community improves it further (for example, upcoming Iceberg spec versions will add new features like row-level column encryption, finer-grained change tracking, etc., driven by real-world needs).
Apache Iceberg, backed by this solid architecture and thriving ecosystem, truly realizes the vision of a unified, high-performance data lakehouse. It empowers organizations to build data platforms that cater to BI analytics and AI/ML alike, in cloud, on-prem, or hybrid settings, all on top of open and vendor-neutral infrastructure. With the integration of engines like DuckDB and the support from cloud giants, Iceberg’s role in modern data stacks is set only to expand in the coming years – bringing ever more flexibility and power to data professionals.