
Building an open data pipeline in 2024
Using Iceberg allows us to pick the optimal "big data" compute environment for the specific requirements we have. There's no need to limit yourself to a single solution.

In a previous post on the commoditization of SQL, I touched on the concept of building a data stack that harnesses this approach. One key element of this architecture involves utilizing Iceberg as the core data storage layer, with the flexibility to choose the most suitable compute environment depending on the specific needs of your use case. For instance, if you’re powering BI reporting you’ll often want to prioritize speed so your customers can quickly get the data they need. Conversely, cost may be the biggest factor if you’re working on a batch data pipeline job. Additionally, you may have external data customers in which case you want to prioritize availability over everything else. While there is no one-size-fits-all solution, understanding your unique use cases and requirements allows you to tailor your approach accordingly.
Understand your requirements
There are a few dimensions here and I want to go through each of them separately although in practice it’s going to be a combination of factors.
Data Scale

We live in a world of “big data” but even within big data we have entirely different tiers. Smaller data sets can be handled using DuckDB on a single node instance. Larger data sets require some sort of map-reduce approach and can leverage modern data warehouses, such as Snowflake or Databricks. And if you’re dealing with truly massive datasets you can take advantage of GPUs for your data jobs.
Latency
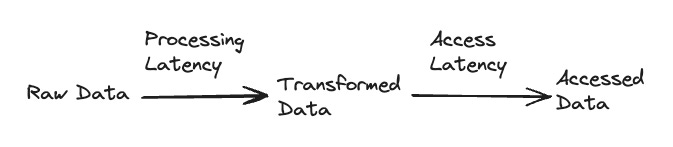
There are two types of latency to consider. The first type is data processing, which refers to the time required to transform and process the data. The second type is the speed at which queries can be executed in interactive or reporting use cases. Imagine you have a service that collects e-commerce transaction data to help customers understand their sales better. You receive an event for every transaction but given the scale you choose to aggregate the data hourly and the aggregation takes 10 minutes to run. When the data is aggregated users are then able to query it via a BI tool and 95% of queries execute within 5 seconds. In this case, your data processing latency is at most 70 minutes but your query latency is a few seconds.
You can improve data processing latency by running the jobs more frequently or on larger hardware. To improve query latency you can have larger hardware and keep as much data “hot” and in memory rather than pulling it from “cold” storage. As with most things, reducing latency will cost you more.
Governance and access controls
In general, managed tools will give you stronger governance and access controls compared to open source solutions. For businesses dealing with sensitive data that requires a robust security model, commercial solutions may be worth investing in, as they can provide an added layer of reassurance and a stronger audit trail.
Different types of data will often have different requirements. Typically, raw events often deal with personally identifiable information and have high sensitivity. However, as the data is rolled up and aggregated, the sensitivity level tends to decrease, allowing for more defined roles and responsibilities around the data sensitivity levels.
Cost
Cost is a function of the above but is also a key dimension on its own. Depending on the economics of your business cost may actually be the constraint that forces you to compromise on some of the other requirements. It can be useful to think of the ideal architecture where cost is not a factor and then keep stripping and compromising as you layer on more and more cost considerations. That also gives you a good sense of your priorities and how to tradeoff between them. For instance, you might realize that achieving sub-second query latency is less crucial than establishing a robust security model.
A helpful approach when thinking about cost is asking the question of what it would look like if you had twice the budget? What about half the budget? That can inspire some creative thinking and lead to solutions that weren’t obvious at first.
Putting it all together
Before starting Twing Data, I gained valuable experience working at TripleLift, an advertising technology company, where I held several engineering leadership positions over the course of 10 years. During my time there, we went through multiple iterations of a data pipeline. Drawing from that experience, I wanted to utilize the framework mentioned above to create an architecture that is specifically tailored to accommodate diverse requirements while leveraging Iceberg and the different compute environments available.
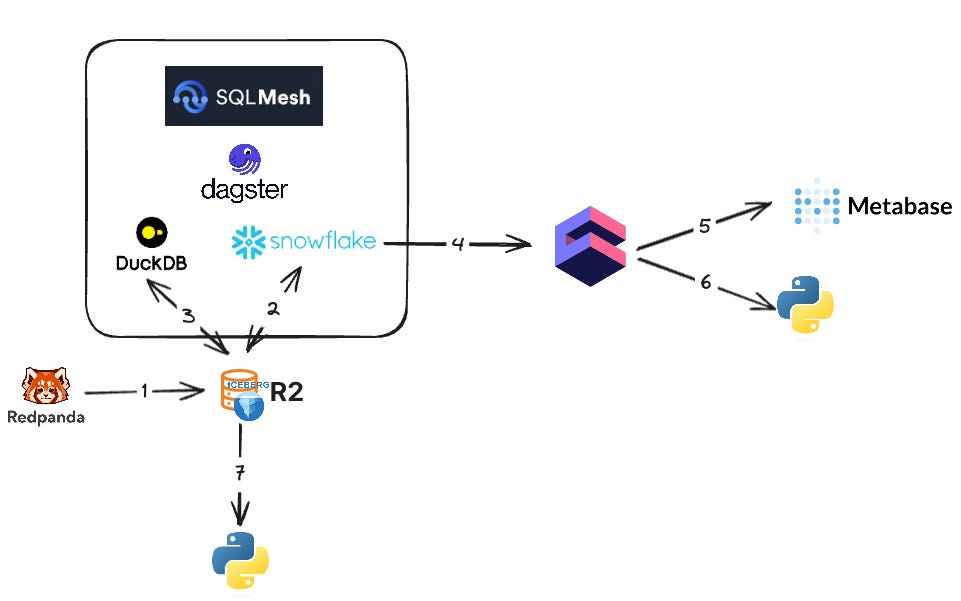
Here’s a breakdown of how it fits together.
Log-level events are collected in Redpanda and persisted to Cloudflare R2 (better than AWS S3) using Parquet and Iceberg. There are hundreds of billions of events each day and range from information about the advertising auctions being run, to the winners of each auction, to collecting information around whether the ad was viewed and for how long.
Data modeling is done using SQLMesh and orchestrated in dagster. Complex transformations that require distributed work with large-scale joins run in Snowflake. One example is joining all the events from the first step in order to create a wide table where each row represents everything we know about a single auction.
DuckDB is used for simpler jobs that can run on a single node. For example, taking the wide and large table from the second step and coming up with smaller tables that have a subset of the dimensions and are highly aggregated.
Cube is used as a semantic layer to give us a standard way of defining the metrics we care about and ensuring they are consistent across multiple access paths.
One access path is Metabase which acts as our BI tool. By going through Cube we can ensure we use standard definitions and take advantage of Cube’s pre-aggregation/caching layer.
Some of our engineers use Python directly and can also take advantage of the semantic layer offered by Cube.
We also want to allow power users, such as data scientists, the ability to query the data directly from R2 using whatever compute layer they want. They may want to use Spark or even Snowflake but they’re able to because the data is stored using an open storage format, Iceberg.
This approach is centered around Iceberg and its open nature. In the above example we can switch Snowflake with Databricks without any trouble. Moreover, we have the flexibility to adopt different orchestration, data modeling, and semantic layers as needed. The foundation of this flexibility lies in the fact that the core of the system, the data itself, is not confined to a proprietary format. This not only leads to cost-effectiveness but also fosters innovation as both you and the ecosystem expand and evolve.