
Handling Personal Data Deletion in AdTech Data Systems
We’re outlining four approaches to data deletion and evaluating tradeoffs between them.

In many software engineering disciplines, data can be ephemeral. Say you have a buggy API — you can deploy a new version and the past is forgotten. But data engineering has a lot more state, and is far more sticky as a result. Once you collect some data, it’s likely that it will stick around for years and you’re going to have to support it.
A common challenge every company has to deal with is personal data. As a consumer, you want to make sure companies are protecting your data, or ideally not even storing it in the first place. Various regions, countries, states, etc have their own regulations. Europe has GDPR, California has the CCPA, Canada has PIPEDA, Brazil has LGPD, and so on.
Adtech data tends to not be as sensitive as others — we’re not dealing with government identities or payment information, after all — but there is the matter of user browsing data. For example, if you’re using a browser that supports third party cookies (like Chrome), your behavior can be tracked from site to site, and companies pay to generate a targeting profile for you. If you’re using a browser that only supports first party cookies (like Safari) you can’t be tracked as easily across sites, but your browsing behavior is still captured within the same site.
For this reason, the aforementioned regulations often have a requirement around data deletion requests. If you’re storing this personal data, you have an obligation to delete it when asked. The types of data that qualifies as personal data varies between companies and industries, but for adtech it’s typically the user id, IP address, user agent — anything that allows you to identify and track individual users.
Going back to deletions, in a typical database, the deletion would be a simple “DELETE FROM TABLE WHERE user_id = ‘abc’” — but adtech data isn’t stored in a simple database. Instead, we have hundreds of billions of records that have some personal data captured each day and for cost reasons usually stored on S3 in some compressed and analytics-optimized format, such as Parquet.
So what do you do when a user wants to delete their data? The cookie that’s stored in the browser is easy to delete, but what do you do with the trillions of rows scattered across these Parquet files going back for months? You can run the “DELETE FROM TABLE .. “ command above, but what it will do is read the terabytes/petabytes of data into memory, filter and remove the relevant rows, then write it back to S3. It’s doable, but it’s slow and incredibly expensive. Think on the order of thousands or tens of thousands of dollars for a single user deletion request. It’s not obvious how to do it.
Four Approaches To Data Deletion
Don’t store the data at all
What’s not stored doesn’t need to be removed. But that comes at a cost: the data is needed to run a variety of analyses. Being able to count the distinct numbers of users, calculate trends, or use the data to cluster users to create these advertiser audiences in order to improve your ad targeting and hopefully improve the return of your ad spend.

Best for: Strict compliance and lowest storage and compute cost.
Tradeoff: The data is not available for analysis.
Store the data for a limited time
Alternatively, store the data for the minimum time you need, and then purge the rest. There’s still a cost to the removal, but if you only retain this data for a week then your deletion query only needs to run for a week’s worth of data.
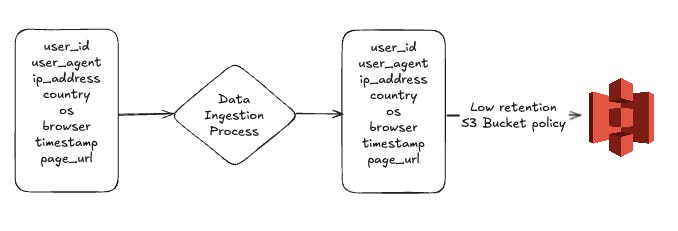
We can extend the above to be even better by storing the personal data separately. Instead of storing the personal data in the same files as the rest we can split it into multiple file types with their own retention policies. That way the personal data can have a shorter retention window and you avoid having to run the deletion request on the full dataset. This allows the non-personal data to still be used for analysis and investigations without incurring the cost of storing the personal data.

Best for: Having some personal data available with low operational costs.
Tradeoff: Deletion still costs money, but the cost and likelihood of needing to run a deletion is low.
Store hashed values instead of original values
With this approach, the data isn’t tied back to the original user, but you are still able to run the bulk of the analysis you did originally. You still delete the cookie in the browser, but at that point the link is broken and you can let the data naturally phase out based on your retention policies. The key here is that if a deletion request comes in, you only have to remove it from the browser. No need to worry about the data stored in S3.

Best for: Having long term pseudonymized personal data available for a subset of analyses (counts, discount counts, various grouping).
Tradeoff: You cannot easily map this data back to the original user id, which limits the ability to associate properties with users — for example, associating users with a specific advertising audience.
Use a mapping table
The challenge with the one way hash approach is that it’s still deterministic. If you know what the user’s cookie id was and the hashing approach, you can rederive the hashed value. But we can make the association truly random by generating a completely random id, then using a mapping table to connect the cookie id to a random id that will be what’s stored in the S3 logs. When a user submits a deletion request, we purge the mapping entry, breaking the link similar to the prior approach, also letting it phase out naturally with the retention policy. Similar to the solution above, we remove it from a much cheaper and quicker data store — the mapping table — without having to touch anything on S3. As part of this step, we can also do full anonymization on the fields we don’t need details for; for example, just mapping user agent to a browser version, and stripping the last octet of the IP address.

Best for: Being able to do advanced and robust analysis and audience creation.
Tradeoff: This is more operationally complex and costly than the others.
For each of these strategies, it’s all about evaluating tradeoffs. Product and data science teams typically want as much data as they can get, since it’s what they use to innovate. On the other hand, legal and compliance teams want to limit the risk. And the data engineering teams are charged with walking that tightrope, all while keeping costs down so they can work on other problems. It’s no easy feat, but we hope these approaches help you think through the best approach for your team.