
Handling Truncated Insert Queries using Regex and ChatGPT
We used ChatGPT to generate a Regex that we ran through a battery of tests to handle truncated INSERT query text.

At Twing Data, one of our primary goals is to parse every query that runs on a customer’s data warehouse. This allows us to extract key information such as tables, columns, their relationships, and other details that help us gain a deeper understanding of the data.
As expected, each warehouse has its own way of exposing the query history log. That topic warrants a separate discussion but in this post I want to cover handling truncated queries. This particular customer uses Snowflake and while Snowflake’s query history is great it caps the query text at a supposed 100,000 characters. During the ingestion of this customer’s data our monitoring system flagged that some queries had invalid SQL syntax which prevented parsing.
When analyzing data and code, it’s useful to examine the data from multiple perspectives. In this case, a high-level approach allows you to examine the query length distributions and get a sense of how often queries are being cut off. A low-level view, on the other hand, lets you sample a few queries to understand why the query is being truncated and why the text is so long. Once you have both of those you can take a mid-level approach to identify a broader pattern.
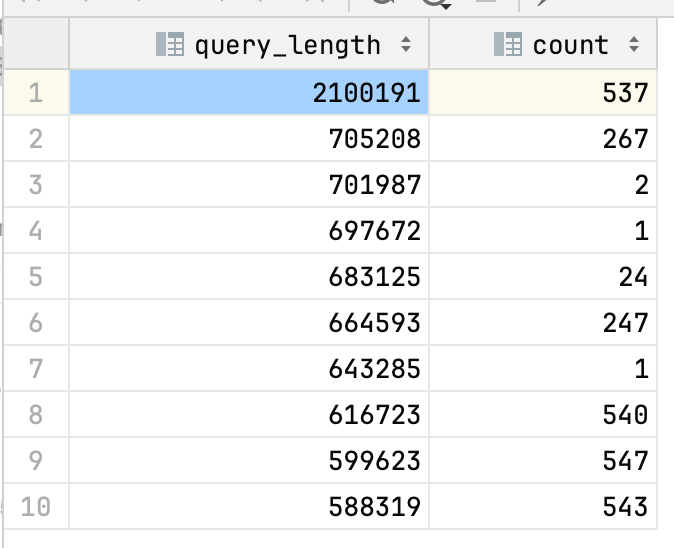

In this case, it turned out that they were all of the form “INSERT INTO table_name VALUES (..)” with tens of thousands of value rows. This was actually great for us since at the moment we do not analyze the values themselves, only that there was a manual insert being done into table_name.
Now that we had a cause, we wanted to deal with it. Since our analysis relies only on knowing that there was an insert being done we decided that the cleanest approach was to only keep the first set of insert values. So any INSERT .. VALUES query becomes a single row INSERT. The side benefit of this was that the parsing code became much faster.
Regex and ChatGPT to the rescue
Some people, when confronted with a problem, think "I know, I'll use regular expressions." Now they have two problems. - Jamie Zawinski
The common advice is to avoid regular expressions and the more you experience the more you appreciate it. In this case though, we decided that the risk/reward tradeoff was in our favor. Additionally, this gave us a chance to leverage ChatGPT. Rather than spend time crafting a perfect regex we wanted to see what ChatGPT could come up with given a few examples. We took an iterative approach by generating a handful of unit tests and then prompting ChatGPT to keep iterating until it got to what we wanted. After a few iterations we had something useful.


# Unit tests we have
q = "SELECT a from b"
self.assertEqual(simplify_long_insert_value(q), q)
q1 = "INSERT INTO dest VALUES (1, 2, 3)"
self.assertEqual(simplify_long_insert_value(q1), q1)
q2 = "INSERT INTO dest VALUES (1, 2, 3), (4, 5, 6)"
self.assertEqual(simplify_long_insert_value(q2), "INSERT INTO dest VALUES (1, 2, 3)")
q3 = "INSERT INTO dest VALUES (1, 2, 3), (4, 5, 6), (7, 8, 9)"
self.assertEqual(simplify_long_insert_value(q3), "INSERT INTO dest VALUES (1, 2, 3)")
q4 = """INSERT INTO "a"."b"."c" VALUES ('1', '2', '3'), ('4', '5', '6'), ('7', '8'"""
self.assertEqual(
simplify_long_insert_value(q4),
"""INSERT INTO "a"."b"."c" VALUES ('1', '2', '3')""",
)
q5 = """INSERT INTO "a"."b"."c" VALUES ('1','abc','','','','https://www.1.com','','','','','','','','XYZ"""
self.assertEqual(
simplify_long_insert_value(q5),
"""INSERT INTO "a"."b"."c" VALUES ('1','abc','','','','https://www.1.com','','','','','','','','XYZ""",
)
q6 = """INSERT INTO a VALUES ('1', '2', '3'), ('4', '5', '6'), ('(2)"""
self.assertEqual(simplify_long_insert_value(q6), """INSERT INTO a VALUES ('1', '2', '3')""")
q7 = """INSERT INTO a VALUES ('1 (a)', '2', '3'), ('4', '5', '6'), ('(2)"""
self.assertEqual(
simplify_long_insert_value(q7),
"""INSERT INTO a VALUES ('1 (a)', '2', '3')""",
)
q8 = """INSERT INTO a VALUES ('1 (a)', '2', '3),'), ('4', '5', '6(dasdsa)"""
self.assertEqual(
simplify_long_insert_value(q8),
"""INSERT INTO a VALUES ('1 (a)', '2', '3),')""",
)This is a post we enjoyed writing. It highlights both the real world challenges we face in trying to parse every query we see but also gives a glimpse into the way we software development is evolving. It’s not just human or just AI but a product of both that lets you play to the strengths of each.
About Twing Data
Twing Data helps companies understand their data warehouse by analyzing the query history of a data warehouse. We extract tables, columns, and their usage patterns and use this information to highlight unused and infrequently used data assets, complex data definitions that are good candidates for refactoring, and flows that deserve a deeper look. Teams use Twing Data to reduce costs, improve performance, and drive simplicity of their data warehouse.