
Make API Data Engineering Fun with DuckDB
An example of using DuckDB to simplify the often frustrating API to database workflow


These days so much data engineering work is paging through an API, parsing the responses, storing them in a database, and then joining them with other data to build an actually useful product.
It’s not glamorous work. In fact, it’s a grind dealing with the various APIs and figuring out the right incantation of parameters to get the data you want. Not to mention dealing with failures, rate limiting, undocumented “features,” and everything else under the sun.
And after you have the data, you have to parse the results and transform it iso it’s easy to work with, and join with the rest of the data you have.
What’s worked for us is integrating DuckDB into our analysis workflows. For those unfamiliar, it’s akin to running a small data warehouse within your script. It has a standalone mode, but you can also simply “import” it into a Python script and interact with it with SQL just like you would with any database. It’s basically an OLAP version of sqlite.
A sample project we’ve done is to fetch some data from a customer’s database and then hit the vendor API with those ids to enrich the data. This vexing workflow becomes a lot simpler (and maybe even fun) with DuckDB.
The basic idea is to just dump the API responses as JSON into a directory and then use DuckDB to quickly query the semi-structured data.
Here’s the basic folder structure:
/script.py
/data/data_type1/file1.json
/data/data_type1/file2.json
Steps:
Pull the ids you want to enrich
This can be from the database or another API. The key thing is that this is just a simple list without the details since those need to be retrieved via a separate API call.
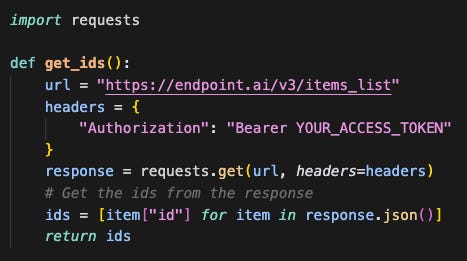
Pull the ids you already pulled from the API
We want to be efficient and not refetch data we already have. In this case we can use DuckDB and do something like SELECT distinct(id) from read_json_auto(“/data/data_type1/*json”); to get the unique set of values we already have data for.

Compare the two and fetch the new data
Generate the set difference between steps 1 and 2 above to identify the new data we need to fetch and then run the script to fetch the data from the APIs. The result of this can be dumped into the data folder above as simple JSON without worrying about parsing or any transformations. Just dump it into the folder. For larger tasks you can also parallelize the calls to run through the fetches quicker.
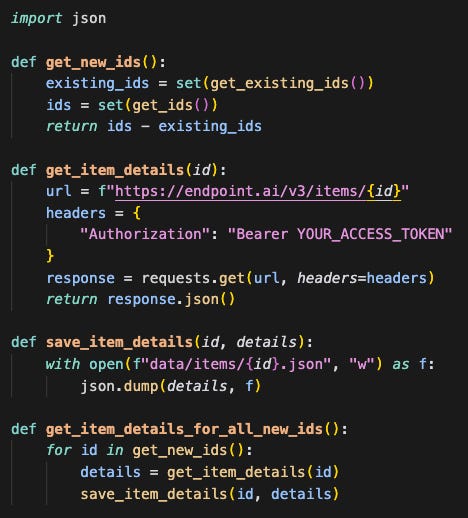
Use DuckDB to bulk read the JSON data
Now this is where DuckDB shines. We can use the “read_json_auto” function to convert the semi-structured JSON data into a proper table we can query via SQL. If it’s a small project you can just query it directly. Otherwise, you can persist it and make it joinable with other data sets.
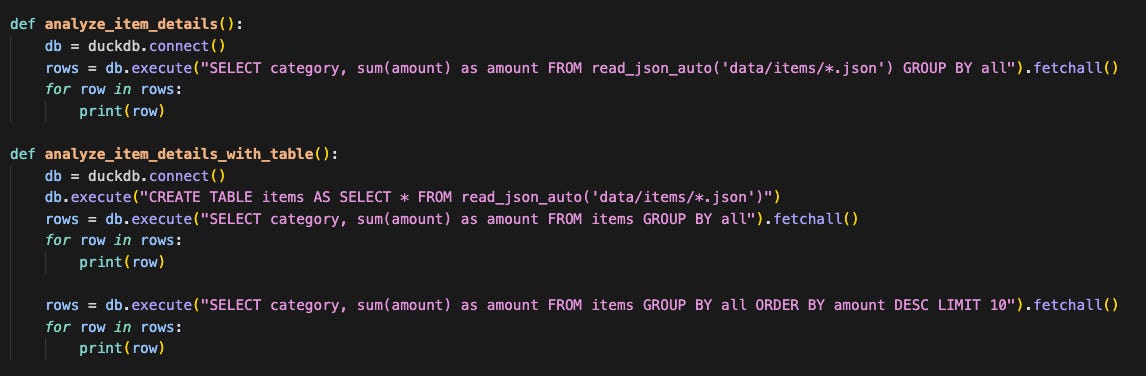
Profit
It’s an incredibly powerful tool and worth considering as part of any data transformation workflow. Dealing with APIs and polling and transformations is never fun – but DuckDB makes these workflows much better.
Full code here.