
Redshift Serverless Pricing
A Comprehensive Overview


To continue the Redshift pricing topic introduced in my previous blog, The Real Cost of Redshift Warehousing, I want to zoom in on Redshift Serverless. This product can be a major convenience for the right user, but it’s vitally important to understand the documented, and undocumented, details that govern their pricing policies in order to evaluate if it’s the right choice for your company.
In case you haven’t read my previous blog or are otherwise unfamiliar with Redshift Serverless, let me quickly outline the basics. The term “serverless” means that you don’t need to manage the servers—the provider handles all the heavy lifting behind the scenes (even though, of course, servers are still there). In a serverless data warehouse, the infrastructure is fully managed for you, scaling automatically with usage so that you only pay for the compute you actually use, with storage priced separately. Redshift’s take on a serverless system follows this model, though with some high-impact nuances that are the focus of this post.
Limitations of Redshift Serverless: Looking Under the Hood
When considering whether or not Redshift Serverless is right for you, it’s essential to understand what it actually is in contrast to a true serverless system like BigQuery, and how it can more accurately be thought of as a version of their typical provisioned cluster. To establish a frame of reference, let me explain a bit about both truly serverless systems and the Redshift provisioned cluster:
As an example of a true serverless system, BigQuery, Google’s cloud data warehouse offering, was built from the ground up to provide all the hallmarks of this class: a shared compute pool dynamically allocates resources to tenants as needed, charged only for use, and storage is handled completely independently, billed per MiB per second. To be sure, BigQuery is a feature-rich solution with many configurations and an option provisioning compute as well, so I am simplifying here.
A provisioned cluster is Redshift’s standard system option in which the user defines the attributes of a cluster - like node size/type, its execution behavior - like Workload Management (WLM) or Short Query Acceleration (SQA), as well as its scaling boundaries, as in Concurrency Scaling and Elastic/Manual Resize. Storage either falls within Redshift Managed Storage (RMS) or uses external S3 and is accessed at a small premium via Spectrum. RMS capacity is linked to cluster composition, as different node sizes/types offer varying max RMS capacity per node. In this way, while storage is priced separately, it is yet tied to compute. A provisioned cluster offers the cheapest per-unit compute pricing, but not only do charges accrue as long as it’s running, even when idle, but also potentially requires an enormous amount of configuration, monitoring and management across both workloads and storage to achieve reasonable cost and efficiency.

TL;DR: A Redshift cluster is an isolated instance with relative compute and storage limits managed at the individual level and rented by the hour, while a traditional serverless system decouples storage and compute, scaling them independently and pricing on demand.
With these differences in mind, let’s now examine Redshift Serverless. While traditional serverless leverages multi-tenant compute infrastructure, Redshift Serverless, under the hood, is actually running on clusters of nodes identical to those that can be configured and run manually. Rather than accessing a shared, always-on system of clusters for compute, Redshift’s version merely manages an isolated system on the user’s behalf and prices compute in Redshift Processing Units (RPU). It’s important to understand this for a few reasons:
RMS storage has limits. Serverless storage limits are addressed in exactly 1 bullet point in the docs, and if you miss it, you could reasonably be under the impression that it scales limitlessly, automatically, and only increases Redshift Managed Storage (RMS) costs. This is not true. RMS has max capacity based on node types and counts in the cluster in use. The minimum RPU settings essentially define the amount of available RMS. If data volume exceeds that max capacity, the minimum RPUs that will be used for any workload will be the number that can handle the needed amount of storage. The way to work around this is to manually place a portion of the data in external S3. While Spectrum is required to scan external S3 data, its use is included in the per RPU pricing.
“On-demand compute” is not always available on demand. Even when no compute resources are being used, there are ongoing costs for things like hardware maintenance, power, and cooling. With an on-demand pricing model, customers only pay when compute is in use, but the host still has to handle these ongoing costs. In a truly serverless system, a multi-tenant architecture manages this by balancing resource usage across many customers, which helps reduce waste. Amazon’s version of serverless boasts on-demand pricing, yet manages resources at the level of individual accounts. There’s no mechanism to pass unused resources from one account to another. Do they simply eat the cost of idle resources for their inactive serverless customers? Absolutely …not. After 1 hour of idling, the instance fully deactivates. When it’s inevitably needed again, the entire cluster has to reactivate first, which, in our experience, can take up to around 10 seconds. If the efficiency of that workload was business-critical, RIP. Since the one-hour deactivation threshold isn’t adjustable, your only options are to schedule important queries within an hour of another query or to send periodic pings to keep the system active.
Redshift Serverless Minimum Pricing Nuances: The Risk of Blind Trust
Minimum Charge Policy: “You pay for the workloads you run in RPU-hours on a per-second basis, with a 60-second minimum charge.”
On first pass the policy seems aggressive but pretty straightforward. A naturally-emerging follow-up question, “How many RPUs factor into that minimum?” actually has an innocent answer: your base (minimum) RPUs. Even if we stop here and assume that’s all there is to it, it’s clear that without purposefully managing your workloads around the minimum charge policy, your warehouse bill will likely be many times what it should.
We’ve indeed found Redshift’s minimum pricing policies to have an outsized impact on our clients’ warehouse costs. And not just because the policy is completely overlooked. The docs are actually deceptive on this topic. What constitutes “...workloads you run…” is actually a combination of the queries you execute and system queries related to the environment and metadata tracking processes. Also included are mysterious seconds that I haven’t been able to account for. Consider the following query and results:
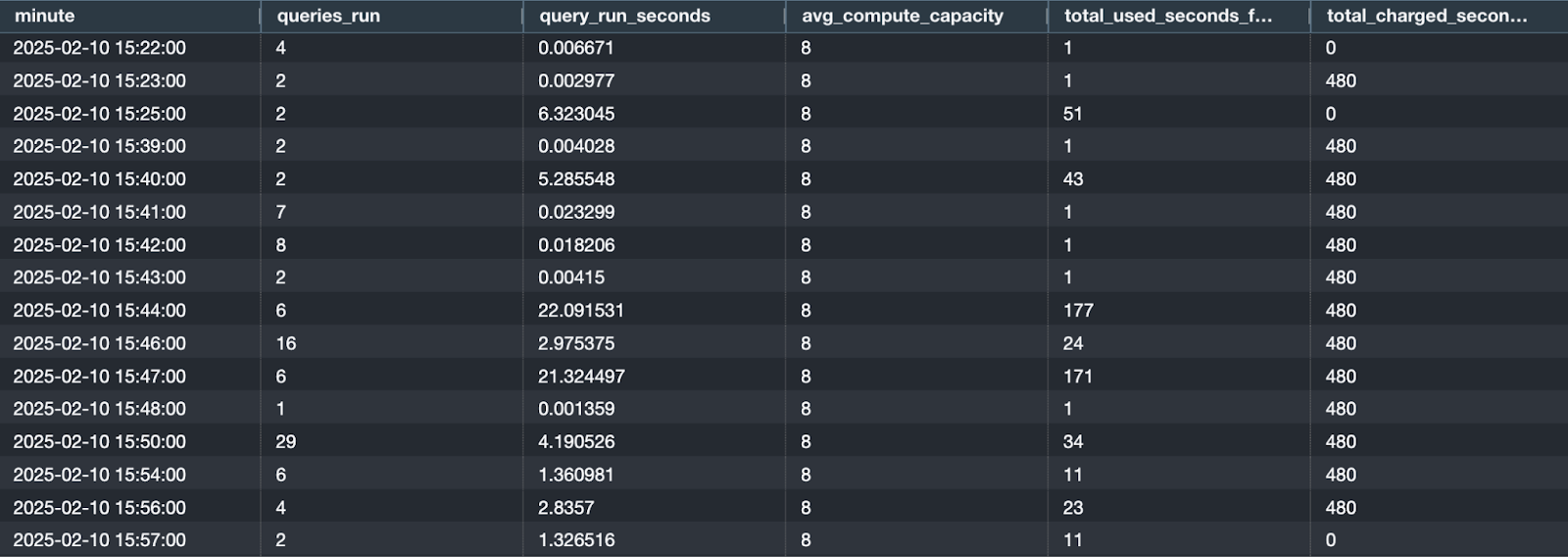
Since this is rolled up by minute, you might assume that query_run_seconds should be the same as total_used_seconds. That’s quite a discrepancy! 22 seconds -> 177? There’s even more: in any of these minutes I actually ran between 0 and 2 queries. Queries logged to sys_query_history include those which ran automatically as part of background processes, which may or may not be directly associated with the workload you ran. To understand what’s happening, let’s dig in to examine the queries logged for minute 15:46:00:

The highlighted queries are the ones I wrote. The last one wasn’t even run in that minute, but added to 15:46:00 later. Everything else was often-redundant metadata fetching or tracking/validation behavior related to the environment or systems. 3 queries became 16. At least they’re fast. But, given that the total query_run_seconds for all 16 queries is 3 seconds, yet the calculated total_used_seconds is 24, we can guess that there are some major associated, undocumented processes that accrue to sys_serverless_usage.compute_seconds. Here’s an even more surprising example from a few minutes previous:

I ran 1 query during this minute, and it maybe took a second or two. RS recorded 3 runs of the same query, one taking 22 seconds! Then, the total ~22 query_run_seconds recorded for the entire minute translated to 177 seconds used. A two second query run became 177 seconds “used”!
For this experiment I used the smallest base capacity possible, and didn’t dare go over the minimum charges per minute. In the real world this sort of behavior can lead to massive overspend. I wish I was able to wrap this up with a recommended implementation, and perhaps we’ll discover one and write a blog. The conclusion to make so far is that this behavior must be monitored. At a certain scale of overcharge, managing your own cluster might be worth considering.
Who Benefits From This Setup?
As a rule, abstracting away lower-level complexity introduces various types of costs that are difficult to track and sometimes impossible to correct. Serverless systems have some degree of this issue by nature, prioritizing simplicity and efficiency at a premium price. I would not put Redshift Serverless in this category, though. While it nails the premium price tag, the simplicity and efficiency are not included to the same degree. Where true serverless systems are built from the ground up to benefit from the scale of distributed compute and separate storage, Redshift’s version is merely a repackaging of the same isolated system offering, with some abstracted optionality based on an arbitrary, derivative metric RPU. No shared, always-on compute pool, no care-free limitless storage, but you will get a black box management layer that partially obstructs the visibility into how it operates.
On the positive side, if your stack already includes other AWS products, RS Serverless does earn simplicity points, as AWS products integrate nicely together. And if you’re otherwise a prime candidate for a serverless warehouse (ie: lacking monitoring knowledge/resources or have uneven/uncertain workloads) it might still be the best option for you. Just make sure to deliberately set usage limits and base capacity (default is 128 RPU, which may be too much).
At Twing Data, we use our warehouse-agnostic query parsing and analysis system to help our clients surface and diagnose a variety of inefficiencies, anomalous behaviors, and antipatterns across the data stack. We are always pushing to better understand our clients’ stacks. If you have insights into how to best use or understand Redshift Serverless, please reach out, or, better yet, leave a comment here for others to find!